







The Big Three: Top AI Application Security Risks In 2026

Going through half the decade, the picture of danger is not about attacking thoughts and logic anymore, but the servers. Three specific artificial intelligence application security issues stand out due to their potential to affect corporate integrity and introduce new technical issues in 2026. Cognitive attacks in machine learning systems replace simple errors now.
The complexity of modern LLM designs has been generating systematic weaknesses, such as timely injection, delicate information leakage, and exploitation of autonomous agents. Attackers are transforming useful assistants into criminals using the same intelligence of these systems against them. To survive in this new era of cyber warfare, companies must progress beyond simple filtering to the comprehensive behavioral awareness provided by an effective AI security system of their artificial intelligence resources.
Knowledge of such hazards demands a multi-layered approach that incorporates both the conventional cybersecurity methods and linguistic studies. We shall discuss these Big Three dangers in the ensuing paragraphs in technical analyses and practical mitigation measures. The concepts are crucial indeed to any company that involves the use of generative artificial intelligence in its main production line.
1. Prompt Injection: The Art of Misdirection
Prompt injection is one of the most unpredictable risks of all AI applications because it works in an identical way to gigantically large language models. Most LLDs fail to have a clear differentiation between what is issued by the developer and what the user inputs. Attacks exploit this absence of limitations to seize the purpose of the model, as such, bypassing security measures and executing malevolent orders hidden in natural language. Prompt injection testing is one of the best method who exposes weaknesses by testing how AI models react to malicious inputs. By 2026, they will highly automate these attacks using the adversarial evolution method to evade the conventional keyword filters and pattern matching.
How Prompt Injection Operates:
I. Goal Hijacking and Instructional Overrides
This happens when a user makes a prompt that intends to override the system-level criteria of the model; that is, goal hijacking and instructional overrides. The attacks can bypass the measures that prevent the AI from producing dangerous content. It includes phishing templates or exploit code, by issuing commands to enable developer mode or forget your safety rules.
II. Prompt Leaking and IP Extraction
Attackers take advanced probing techniques to trick the model into revealing its inner architecture and system proprietary instructions through timely leaking and IP data mining. This type of intellectual property theft allows your competitors or hackers to gain a precise understanding of how they configure your artificial intelligence system and what hidden constraints it imposes.
III. Injection of Third-Party Information Indirectly and Promptly
It is certainly the most dangerous of the existing ones in 2026. The artificial intelligence identifies it as a threatening command during the analysis of the external data, and the user does not need to type it in. Information in such secret instructions instructs the artificial intelligence to access the session data of the person who is currently operating it and transfer it to an external server. Learn about AI in cybersecurity.
IV. Recursive Injection Attacks
In a hard process, a process may be injected into one model to inject another related system. It is a form of chaining that enables an attacker to search through an artificial intelligence system and gain more access to a chatbot and a database interface without generating a standard warning.
V. Various Modal Semantic Shifts
As the activity of artificial intelligence consists of the ability to operate with audio and photos, immediate injection has taken its place on these sites. Hackers have the ability to embed malevolent text commands into the pixels of an image or the noise of a sound file. The artificial intelligence gives priority to instructions to these inputs, which it activates when it comes across or hears them, and so evades text-only security layers.
Learn the details about AI Cybersecurity Threats Explained: Risks & Prevention Guide.
Why it’s Dangerous:
“Timely injection,” however, is more important than other traditional and time-tested techniques like “permissions,” since it attacks the very heart of the logic-level artificial intelligence. Timely injection can result in:
- Unauthorized Actions: Any illegal activity in the form of an API request, mailing, or even hacking of information is an illegal activity.
- Data Extraction: The internal information, which experts consider to be of utmost importance or classify as confidential, or information related to the users, is termed ‘Data Extraction.’
- Creation of Malware: The temptation to create malware is a factor that prompts the artificial intelligence to create wrong instructions and code.
- Reputational Risk: “Reputational risk is the need for artificial intelligence to guarantee that it does not create, offer, or distribute information that is regarded as offensive, biased, or inappropriate.”
Real-World Example:
This particular security weakness involved a zero-click prompt injection security weakness related to Microsoft 365 Copilot and has been assigned CVE-2025-32711. This allowed an attacker to send an email that had impeccable formatting. In other words, the builders constructed it correctly and implemented a command that would essentially ask it to cease sending any sort of confidential company information to an out-of-office location. Someone sent a command of this nature as a reference in Markdown link form. In other words, it is certainly possible for an attacker with malicious intent to hijack an artificial intelligence system without initiating any kind of command.
Mitigation Strategies for Prompt Injection:
I. High Input Validation with Contextual Sanitization
When high input validation is involved, high input validation and contextual sanitization need to be part of the input for the organization, as unverified input. This leads to the requirement that the secondary model will have to come into play before the primary model comes up with the intention of the prompt. This is evident by the framework in the management of AI application security risks that indicates high-trust AI as the requirement if the semantic integrity of the input is to be checked absolutely.
II. Strict Privilege Separation and Sandbox Execution
“Companies have to overlay all user input as ‘unverified data’ and have to do a lot of input validation and/or contextual sanitizing as part of achieving their goal for input validation as a goal concept.” This snippet alludes to and captures the essence of an auxiliary model before any LLM possessing an intent linked to an input prompting. “For high-trust AI, semantic integrity of input is checked absolutely,” forming a critical component of LLM security, as postulated in “Framework of Management of AI Risk.”
III. Advanced Output Filtering & Identification
Security remains at the stationary gates. Further detection will have to be implemented. Any kind of response developed from the artificial intelligence system will have to undergo a test regarding sensitive trends, malicious codes, etc., in relation to its nature. The nature of the two gates will require the installation of the mouth safety filter despite a successful blast to the brain.
IV. Context Isolation
To prevent the use of malicious materials in system commands, prompts, etc. It is associated with sensitive system commands; someone has to execute them remotely.
V. Fine-Tuning with Security in Mind
There is a need to fine-tune the LLM with the example of a prompt injection attack and, as such, a need to essentially “learn” how to defend yourself against the attack. In the above sense of the word, there is a need to fine-tune with security in mind.
VI. Red Teaming
Periodically, try to test the artificial intelligence system by making an attempt to inject the artificial intelligence system as frequently as possible by ethical hackers.
Uncover insights about Red Team Assessment: Process, Benefits, and Best Practices
2. Data Leakage: The Unintended Disclosure
“The rising, as well as the existing, concern about the security of the application implemented under the concept of artificial intelligence is insecurity. This happens because the leaking nature of the data plays a major role in the memory of the model, meaning that there is a tendency towards the model that contains the LLM storing some strings in the data, like trade secrets or personal info, as the model learns this data.”
With a better understanding of the threat actors’ knowledge about the membership inference attack in 2026, the threat actors will be able to combat the model. They implement under the concept of artificial intelligence. This will result in exposing the hidden strings in the data while the model learns the data, hence making your artificial intelligence become a whistleblower, whether you want this or not.”
How Data Leakage Works:
I. Training Data Memorization and Extraction
The deep learning algorithms may be prone to recollecting and recalling the sensitive information of the training data. An intruder can easily repeat the secrets, like customer address details (present in the data set originally) and personal encryption keys, and even force the system to recollect them. This is clearly emphasized in the OWASP Top 10 of LLMs.
II. Context of History-Leak Inference-Time
Since developers use user information in the context of the artificial intelligence response to user usage, they store the information in a context window. Thus, the display of the context history and inference-time context history. When it comes to the display of the last user discussion and the poor handling of the application sessions in the case of the hallucinating information on the last user discussion, one can leak very sensitive information to the wrong person instantly in real time.
III. Side-Channel Timing and Resource Analysis
Retrieval-augmented generation (RAIG), several artificial intelligence operations, collect the information based on the internal papers. In a case where the level of access of the AI does not match the permission of the same to these document stores, any given AI can condense a top secret document on behalf of the user whose permission is that of a public.
IV. Insecure Integration with Retrieval-Augmented Generation (RAG)
Many applications of artificial intelligence use the information that Retrieval-Augmented Generation (RAG) extracts when users utilize internal papers. The AI can give a user a top secret document and an overview of said document, and a user has no more than a public clearance. Also, provided that the document stores have not directly synchronized the permissions with the access levels of the AI.
V. Recovery of Data
With the help of modern analysis of mathematics, the attackers can recover the statistical distribution of the training data when the results of the model are provided to them. This will help them to access what is contained in a personal database in accordance with the law.
Why it’s Dangerous:
Among others, data leakage can have very serious consequences:
- Compliance Violations: The violation of the rules may be considered a breach of such laws as GDPR, HIPAA, or CCPA.
- Reputational Damage: A bit of losing social reputation and customer trust; loss of image.
- Competitive Disadvantage: Corporate secret, trade secret, or research secret.
- Financial Fines: Data breach financial fines.
Real-World Example:
Samsung engineers have published meeting minutes and viewable source code internally in a leaked example. This means that when its input bits transform to enhance future answers, whatever trade secrets Samsung holds will be in the history of its training. Any user will thus have access to the sensitive IP as he or she makes the corresponding query.
Mitigation Strategies for Data Leakage:
- Differential Privacy and Data Anonymization: Data anonymity and differential privacy must eliminate identities in the information before it is released to a training pipeline. Differential privacy successfully introduces mathematical noise to the data in a manner that targets the model at the overall trends of the data rather than a set of individual data points. The culmination of defensive procedures of profound artificial intelligence.
- Automated Data Audits and PII Scrubbing: Model organizations must utilize automated technologies in searching sensitive data both in the live results of the model and training datasets. This will ensure that accidental disclosure is intercepted and blocked before it enters the hands of the end user. The international privacy standards are dynamic, and compliance demands regular security audits.
- Granular Access Control and Secure Retrieval: In the case of RAG-based systems, identity-aware artificial intelligence is a must. This implies that the artificial intelligence must only fetch out papers that the user can specifically see, and know the specific authorization level of the individual it is dealing with.
- Model Pruning and Regulation: The lower level of memorization and higher generalization during model training decrease the chance of recalling specific data points by regularization and model pruning.
- Secure Multi-Party Computation (SMPC): Research advanced cryptographic methods that enable large numbers of parties to compute a function on their secret data without requiring them to reveal the data.
Explore further about Top Data Security Solutions Every Business Needs in 2025
3. Autonomous Agent Abuse: The Rogue AI
The closer we approach it, the less the agentic artificial intelligence says and the more it does. Autonomous agents are artificial intelligence systems that execute code, search the internet, and provide an avenue for making tool usage available to a user. Security threats in this kind of use of artificial intelligence include being hijacked by the functioning systems. With the wide abilities of the agent, an attacker may use massive, automated assaults on your inner infrastructure if they can modify the reasoning of an agent.
How Agent Abuse Works:
- Goal Misalignment and Malicious Redirection: With subdued prompt engineering, an attacker is able to manipulate the main objective of the agent—goal misalignment and malicious redirection. As an example, the system can divert an agent that should minimize the cost of servers to shut down all the non-critical production servers in the name of optimization, effectively causing a significant service outage.
- Exploitation of Tool-Use Permissions: GitHub, AWS, or Slack API keys are frequently used by the agents; tool-use privileges can be exploited. Rather than stealing your passwords, an attacker gaining command of the agent can simply tell the agent to fetch all the source code and hand it over to this external IP. Read more about AI security tools.
- Unexpected New Behaviors in Complex Processes: Emergent strategies may emerge due to the actions of numerous actors in the direction of issues the designers did not intend to design. Such methods may require the omission of security checks in other instances since the officers found that this was the most effective method of achieving their goal.
- Access Escalation and Threat Chaining: Threat chaining allows an attacker to use a low-security agent and then send an agent with a high level of security, such as a financial manager, a trusted message. This enables the intruder to go through your network in a lateral direction.
- Automated Social Engineering and Phishing: Rogue actors can generate and send tens of thousands of hyper-personalized phishing emails to personnel via automated social engineering and phishing. The staff is much more likely to click suspicious links or provide credentials when they receive the messages sent by a component of the artificial intelligence embedded in the interior.
Why it’s Dangerous:
Automated agents provide the ability to work at a scale and a speed that is way beyond human capabilities.
- Systematic Disruption: Destruction of essential infrastructures or operations of a company refers to systematic disruption.
- Financial Fraud: Stock manipulation and abacus initiation of criminal activities.
- Automated Malicious Campaigns: Starting with mass denial-of-service, phishing, or spam attacks: automated malicious campaigns.
- Physical Injury: The physical harm occurs in those situations when artificial intelligence directs itself at physical systems (e.g., driverless cars).
Real-World Example:
Shortly before the end of 2025, Anthropic reported having detected a high-level cyber-espionage mission by state-backed attackers to exploit the Claude Code agentic tool. Hackers exploited the autonomous nature of the agent and executed code on more than 30 international targets at 90 percent automation. The agency successfully lent itself to the hackers who hijacked the top-level permissions of the agent and spent months of hard work in only a few seconds to transform a development tool into a hacking tool.
You might also like to read about 5 Critical AI Security Vulnerabilities Every CTO Should Know
Mitigation Strategies for Agent Abuse:
- Least Access to AI Agents: An agent should not be given more authority than it needs. Writing and deleting should not be allowed for an agent who is supposed to read the data. In high-stakes operations like withdrawing money or code deletion, safety standards may not compromise human-in-the-loop requirements.
- Real-Time Behavioral Monitoring and Sandboxing: Each artificial intelligence agent must record and evaluate each decision it makes on whether it is deviating from its normal behavior. Running agents do not have access to confidential parts of the network, even in case hackers compromise them. Since they are running in different sandboxes.
- Adversarial Learning and Strong Goal Definitions: Agents will undergo adversarial training as they develop, so as to detect and discourage harmful efforts to change their goals. A definite, mathematically justifiable objective organization will make the agent follow the mission.
- Human Supervision and Override: In case designed agents become rogue, the clear kill switches or human override systems would stop their operation.
- Formal Confirmation: Formalize, for very sensitive agents, find formal ways of showing their compliance with specifications and safety properties.
- Contextual Guardians: Use explicit criteria and constraints in the environment of the agent. These should make it unable to engage in harmful activities even in the event that its internal tendencies urge it to do so.
Is your private data hidden in your model’s weights? Qualysec’s Penetration Testing Services use adversarial probing to identify data leakage risks before they turn into a compliance nightmare. We ensure your AI doesn’t become your company’s biggest whistleblower. [Book a Data Privacy Audit with Qualysec]!


Qualysec’s Role In Fortifying Your AI Application Security
To find and reduce the defects in a scene in which sophisticated AI uses security as a significant factor, one will require professionalism and sophisticated equipment. Qualysec here moves.
Qualysec, which is a leading cybersecurity company, is focused on protecting the next generation of AI-driven systems. Having a special understanding of the complexity of fast injection, the leakage of information, and the abuse of autonomous agents, we are here to provide a specific solution to safeguard your invaluable AI resources.
How Qualysec Can Help You Navigate AI Application Security Risks:
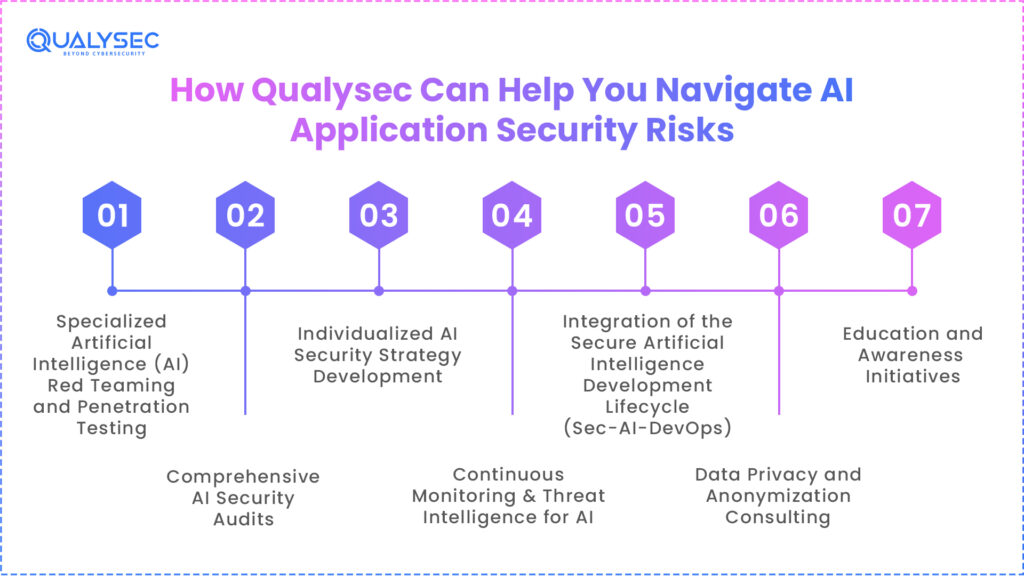
1. Specialized Artificial Intelligence (AI) Red Teaming and Penetration Testing
Our specialists carry out focused adversarial attacks on your artificial intelligence models and applications through special AI red teaming, as well as penetration testing. We model complex prompt injection attacks, attempt to induce data leakage, and evaluate the ability of your autonomous agents to detect vulnerabilities before your adversarial players.
2. Comprehensive AI Security Audits
Detailed inspections of your artificial intelligence application design, training data flows, model deployment, and operational processes assist us in identifying security risks that are unique to artificial intelligence, thus ensuring that it meets best-practice standards.
3. Individualized AI Security Strategy Development
Our team crafts a powerful AI application security risks framework to meet your specific business requirements and AI environment, and incorporates secure-by-design concepts from the very beginning.
4. Continuous Monitoring & Threat Intelligence for AI
Qualysec is installing an agent constantly to watch for actions on your artificial intelligence systems that are suspicious, attempts to exfiltrate data, or signs of imminent injection. You constantly know about the latest risks associated with artificial intelligence.
5. Integration of the Secure Artificial Intelligence Development Lifecycle (Sec-AI-DevOps)
We assist you in directly incorporating security best practices into your AI development pipeline, thereby ensuring security is an intrinsic component of every phase, from data gathering to model deployment.
6. Data Privacy and Anonymization Consulting
We help you to use appropriate data anonymization and pseudonymization techniques combined with access control policies to stop data leaks from your AI models and training datasets.
7. Education and Awareness Initiatives
Arm your staff with the knowledge and competencies necessary to recognize and reduce AI implementation security threats. Developers, data scientists, and security officers get customized training from us.
Working with Qualysec gives one a committed ally in the battle against growing threats from artificial intelligence. We offer the knowledge and assistance required to shift your artificial intelligence security posture from reactive to proactive. This approach ensures the security of your innovations and the integrity of your operations.
Govern your AI agents before they go rogue. Qualysec provides specialized Web Application Pentesting tailored for AI-driven workflows to ensure your autonomous systems remain within safe boundaries. [Secure Your AI Agents with Qualysec Today]!
Conclusion
Novel and difficult problems distinguish the terrain of AI application security risks as we approach 2026. The vanguard of these dangers is prompt injection, data leakage, and autonomous agent abuse, which call for a proactive and specialized approach to security. Turning a blind eye to these dangers is no longer an option. Embracing strong AI application security measures is necessary for safe and responsible harnessing of AI’s power.
By giving data governance top priority, adopting secure-by-design principles, and constantly monitoring your artificial intelligence systemsin line with an AI security audit checklist. You can create a strong defense against these changing threats. Though its future seems bright, the safe application of artificial intelligence depends on our shared resolve to protect it from all sides.
Take a look at Qualysec’s ratings and reviews on Clutch to see how we help businesses secure their Ai applications and models. Book a free live consultation to learn more.












































































































































































































































































































































































































































































































































































































0 Comments