






According to IBM’s 2025 Cost of a Data Breach Report, 13% of organizations reported breaches involving AI models or applications. In 97% of those cases, the affected organizations said proper AI access controls were missing. Model inversion attacks are one example of the growing risks facing AI systems, allowing attackers to potentially infer sensitive information from model outputs. That is not a niche research finding buried in an academic paper. It came from IBM’s analysis of 600 real-world organizations dealing with actual breach events.
Most companies already know how to lock down databases and cloud environments. The blind spot is the model itself. A trained AI system can still expose pieces of the data it learned from through ordinary prediction responses, even when the underlying records remain encrypted and inaccessible. That is where model inversion attacks become a serious problem. IBM’s 2025 findings also showed that 60% of AI-related incidents led to compromised data, while 31% caused operational disruption across the business. Shadow AI played a role in 20% of breaches overall and added an average of $670,000 to breach costs when present.
What Is a Model Inversion Attack?
A model inversion attack is a privacy attack where an adversary uses a machine learning model’s outputs to reconstruct sensitive data from its training set. The attacker does not need direct access to the original dataset. In many cases, repeated interaction with the model’s API is enough to begin reconstructing underlying attributes or records.
The weakness exists because machine learning models do not only learn broad patterns. They also retain traces of the training data itself, particularly when models are overtrained or exposed to highly repetitive datasets. A recent survey research published in 2025 linked this behaviour directly to memorisation and overfitting in deep learning systems. Once that memorisation becomes observable through prediction outputs, reconstruction attacks become possible.
OWASP formally categorises model inversion as ML03:2023 in the OWASP Machine Learning Security Top 10. The project defines the attack as an attempt to reverse-engineer a model to extract information from it. NIST’s AI 100-2 E2025 taxonomy places it under privacy attacks mounted through query access to deployed machine learning systems. Both black-box attacks using API access alone and white-box attacks involving internal model visibility are now well documented in security research.
The regulatory side has also shifted. In December 2024, the European Data Protection Board referenced model inversion attacks while examining whether AI models trained on personal data could themselves fall under the GDPR definition of personal data. That opinion matters because it moves inversion risk out of purely technical discussions and into direct compliance exposure.
How Do Model Inversion Attacks Work?
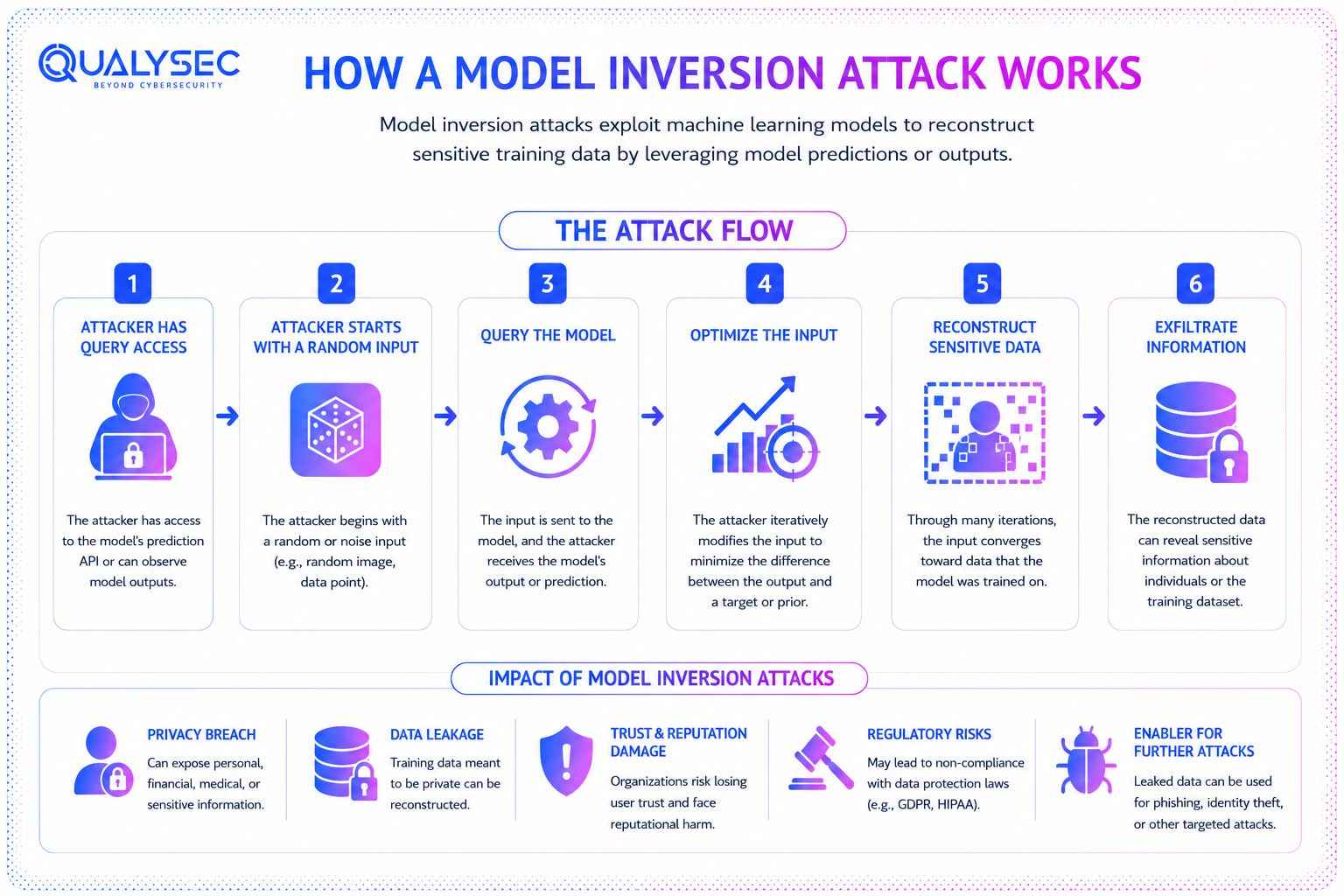
Most model inversion attacks follow a fairly predictable progression, although the tooling and sophistication can vary depending on the target system. In practice, the attack usually starts long before any actual reconstruction happens.
1. Accessing the Model
The first step is identifying how the model can be queried. That could be a public API, a customer-facing chatbot, an internal prediction engine, or even a mobile application connected to a hosted model endpoint. The attacker studies what the system returns with each request. Some models expose only class labels. Others reveal confidence scores, ranked probabilities, embeddings, or detailed prediction metadata.
From a monitoring perspective, this phase rarely looks malicious at first. The traffic often resembles ordinary user activity. NSA, CISA, and the FBI highlighted exposed AI inference interfaces as a primary attack surface in their joint AI data security guidance published in May 2025.
2. Designing Probe Queries
Once the attacker understands the response structure, they begin sending carefully constructed inputs designed to test the model’s behaviour. These are not normal business queries. The goal is to pressure the model into revealing information about the data it learned from.
Researchers have shown that confidence values are especially useful here. Small changes in probabilities across repeated requests can expose statistical patterns tied to specific records or attributes inside the training set.
3. Analysing Output Patterns
At this stage, the attack becomes heavily iterative. Hundreds or thousands of requests may be submitted and compared. Black-box attacks rely on observing changes in output behaviour across repeated API calls. White-box attacks go further by analysing gradients, weights, and internal model parameters directly.
NIST’s 2025 AI taxonomy notes that deployed machine learning systems remain vulnerable to reconstruction-style privacy attacks even when attackers only have query access to the model itself.
4. Reconstructing Sensitive Data
The final phase is reconstruction. By refining inputs and correlating outputs over time, attackers can recover sensitive features tied to the original training data. Depending on the model, that may include facial characteristics, health information, behavioural traits, financial patterns, or biometric markers.
Recent 2025 research has shown inversion methods becoming more effective against multimodal and generative AI systems.
Don’t Let Your Model Reveal What It Learned. Explore our AI Penetration Testing Services and secure your high-risk AI assets.
Consult with our cybersecurity experts
Discuss your unique security requirements and discover how we can help your business.
Model Inversion vs. Model Extraction: What’s the Difference?
Model inversion and model extraction are often discussed together because both target deployed AI systems through repeated interaction with the model. The objective, though, is completely different.
A model inversion attack focuses on the data behind the model. The attacker wants to recover information that appeared in the training set, such as medical records, facial features, financial attributes, or other sensitive identifiers. The model itself becomes the pathway to the data.
Model extraction attacks target the model as intellectual property. Instead of reconstructing training records, the attacker attempts to reproduce the model’s behaviour, architecture, or decision logic closely enough to build a working copy. OWASP classifies this as ML05:2023, or model theft.
One reason security teams increasingly assess these risks together is that they can be chained. An attacker may first perform model extraction to obtain a near-identical copy of the target system. That replica then gives them white-box access, making later inversion attacks far more effective and easier to scale. Recent AI security surveys discuss this escalation path directly.
| Factor | Model Inversion Attack | Model Extraction Attack |
| Primary objective | Recover sensitive training data | Replicate the model itself |
| Main target | Information embedded in training datasets | Model behaviour, weights, or architecture |
| Typical outcome | Exposure of PII, biometrics, medical or financial data | Creation of a functional model copy |
| Access required | Often possible through API-only access | Also commonly performed through API access |
| Main business risk | Privacy violations and regulatory exposure | Intellectual property and trade secret loss |
| Regulatory impact | GDPR, HIPAA, CCPA | IP law, contractual disputes, trade secret claims |
| Relationship between attacks | Extraction can strengthen inversion attacks later | Frequently acts as a precursor step |
Real-World Examples of Model Inversion Attacks
The risks tied to model inversion are not hypothetical. Some of the most cited demonstrations in machine learning security research showed that sensitive information could be reconstructed from production-style models using nothing more than prediction outputs and repeated queries.
Facial Recognition Systems
One of the earliest and most referenced examples came from researchers Matt Fredrikson, Somesh Jha, and Thomas Ristenpart in their 2015 ACM CCS paper. The team demonstrated that recognisable facial images could be reconstructed from a facial recognition model using confidence scores returned by the system. The attacker only needed API interaction and the target individual’s name.
What made the research difficult to dismiss was the quality of reconstruction. A later Royal Society study found that crowdworkers were able to identify individuals from the reconstructed images with 95% accuracy. Even though the original experiments used earlier-generation models, the core attack principles still apply to modern facial recognition systems.
Precision Medicine and Genetic Data
A year earlier, Fredrikson and collaborators demonstrated inversion techniques against a pharmacogenetic model used for personalised warfarin dosing. By combining demographic details with model outputs, the researchers were able to infer sensitive genetic markers linked to individual patients.
That study became important for a different reason. It showed that privacy exposure was not limited to image recognition or consumer applications. Clinical AI systems trained on genomic or treatment data could leak medically sensitive attributes even when the raw records themselves remained protected.
Advertising and Bot Detection
OWASP documents another practical scenario involving ad fraud and bot detection systems. In the example, an advertiser trained their own model to study and invert the behaviour of a live platform’s bot detection engine. The reconstructed decision patterns allowed automated traffic to imitate legitimate human behaviour closely enough to bypass detection.
That matters because inversion is not always about reconstructing faces or medical records. In some cases, attackers use the same techniques to uncover behavioural logic, detection thresholds, or sensitive operational patterns embedded inside production AI systems.
Why Are Model Inversion Attacks So Dangerous?

Model inversion attacks create a problem that most security programs were never designed to handle. The attacker does not break into the database or move laterally across the network. They interact with the AI model exactly the way a normal user or application would. The exposure happens through prediction responses that the system was already supposed to return.
That changes the security equation quite a bit. Traditional controls like encrypted storage, endpoint monitoring, or perimeter filtering may still be working properly while sensitive information continues leaking through the inference layer. The NSA, CISA, and FBI addressed this directly in their 2025 AI security guidance, warning that deployed AI systems remain susceptible to inversion and extraction attacks when model-level protections are weak or missing.
The financial side is hard to ignore. IBM’s 2025 breach research estimated the global average cost of a data breach at $4.44 million. In the United States, the figure reached $10.22 million. Healthcare again recorded the highest losses among all industries, continuing a trend that has now lasted 14 consecutive years.
Privacy regulation adds another layer of pressure. In December 2024, the European Data Protection Board referenced model inversion attacks while examining whether AI models trained on personal data could themselves fall within GDPR’s definition of personal data. If sensitive information can be reconstructed from model outputs, organisations may face mandatory disclosure obligations under GDPR Article 33 or HIPAA breach notification rules. The EU AI Act further increases regulatory scrutiny by requiring risk management and security measures for certain AI systems, especially those handling sensitive personal data.
Biometric exposure is especially difficult to recover from. Credentials can be reset after compromise. Human faces, fingerprints, voiceprints, or genetic markers cannot. Once those characteristics are reconstructed or copied, the risk may persist indefinitely across every system that depends on them for authentication or identification.
Which Industries Are Most at Risk?
The level of risk usually depends on two factors: how sensitive the training data is and how much damage would result if that data were reconstructed. Industries dealing with regulated personal information sit at the top of that list.
Healthcare systems are heavily exposed because modern clinical AI models are trained on diagnostic scans, patient histories, genomic records, prescription data, and treatment outcomes. IBM’s 2025 breach reporting showed healthcare again recording the highest average breach costs across all sectors, with incidents averaging $7.42 million. Containment timelines also remained significantly slower than the broader market average.
Financial institutions face a different operational challenge. Models used for fraud prevention, behavioural scoring, underwriting, transaction analysis, and credit assessment often process deeply detailed customer records. If inversion techniques expose even partial outputs tied to those datasets, the impact can include fraud, identity theft, compliance penalties, and litigation. IBM’s 2025 figures placed the average breach cost for financial services at $5.56 million.
Biometric systems deserve separate attention because the data involved is permanent by design. Academic research from the University of Connecticut described biometric AI systems as strong inversion candidates due to the possibility of reconstructing realistic facial or fingerprint-like inputs from model behaviour alone.
Public-sector and defence environments are also receiving increased scrutiny. The joint NSA/CISA/FBI guidance released in May 2025 specifically targeted federal agencies, defence contractors, and critical infrastructure operators deploying AI systems tied to sensitive operational data.
| Industry | AI Systems Commonly Exposed | Main Compliance Pressure |
| Healthcare | Diagnostic imaging, EHR analysis, and genomic prediction tools | HIPAA, GDPR |
| Banking and financial services | Fraud analytics, behavioural scoring, and credit risk models | PCI-DSS, SOX, GDPR |
| Identity and biometrics | Facial recognition, fingerprint authentication, and palm-vein systems | BIPA, GDPR, CCPA |
| Government and defence | Surveillance analysis, personnel screening, and intelligence support systems | NIST AI RMF, federal AI guidance |
| Insurance | Claims analytics and underwriting systems trained on personal data | Insurance regulations, HIPAA |
Achieve AI Compliance with Confidence
Get expert AI security testing to Secure Your AI Systems and Meet Compliance Standards.
How to Prevent Model Inversion Attacks
Stopping model inversion attacks is rarely about one security product or one setting inside the model pipeline. Most incidents happen because multiple small gaps exist at the same time. An exposed inference API, overly detailed outputs, weak monitoring, and unrestricted query volumes together create the conditions attackers need. The first area security teams usually review is the training process itself.
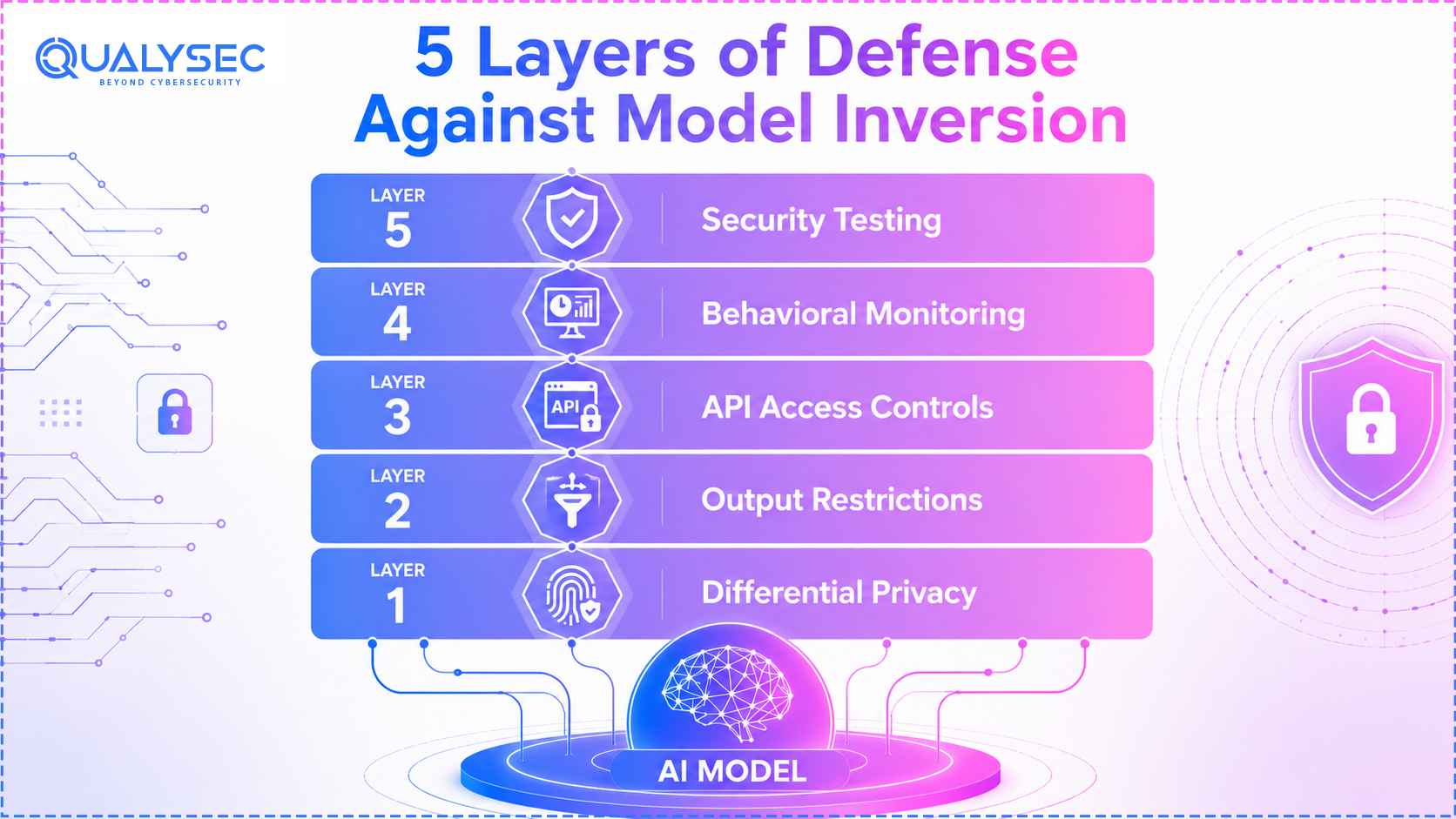
Use Differential Privacy During Training
Differential privacy reduces the chances of individual records being memorised too precisely by the model. Instead of allowing the system to learn exact statistical relationships from training data, controlled mathematical noise is introduced during training.
NIST finalized SP 800-226 in March 2025 to help organisations evaluate the strength of differential privacy protections against reconstruction attacks. The guidance aligns with the NIST AI Risk Management Framework (AI RMF), which encourages organisations to identify, assess, and mitigate privacy and security risks throughout the AI lifecycle.
Sources: NIST SP 800-226, NIST March 2025 guidance
This matters more in environments where models are trained on:
- patient records and medical imaging
- facial recognition datasets
- behavioural profiling data
- financial transactions
- biometric identifiers
A surprising number of enterprise models still move into production without any privacy-preserving training controls at all.
Limit What the Model Returns
Many inversion attacks depend on confidence scores. The more detail a model exposes, the easier it becomes to map patterns across repeated queries.
A system returning a simple classification label exposes far less information than one returning:
- ranked probabilities
- confidence percentages with multiple decimal points
- embeddings
- full prediction metadata
- token-level scoring outputs
Fredrikson’s 2015 research showed that even basic confidence-score rounding reduced reconstruction quality noticeably.
Sources: Fredrikson et al. ACM CCS 2015, OWASP ML03:2023
Treat AI APIs Like High-Risk Assets
A public-facing model endpoint should not be treated as a normal application API.
The May 2025 NSA/CISA/FBI guidance specifically recommended:
- role-based access controls
- immutable inference logging
- authenticated model access
- strict query-rate controls
- monitoring around output distribution shifts
One issue many teams miss: inversion attempts often look like valid usage early on. The traffic does not always appear malicious until query patterns are analysed over time.
Source: NSA/CISA/FBI AI Data Security CSI (2025)
Monitor for Behaviour That Does Not Fit Normal Usage
Most legitimate users interact with models in predictable ways. Attackers usually do not.
Repeated boundary testing, abnormal query sequencing, synthetic inputs, and unusually high inference volumes tend to appear during inversion attempts. Teams that baseline normal API behaviour generally detect these patterns earlier than teams relying only on perimeter monitoring.
That operational layer matters because prevention controls are not perfect. Detection still matters.
Security Testing Still Matters
A lot of organisations assume their AI systems are safe because the surrounding infrastructure passed a security review. That does not automatically mean the model itself was tested for inversion exposure.
Questions security teams should be asking include:
- Are confidence scores unnecessarily exposed?
- Can inference endpoints be queried at scale?
- Are model outputs logged and reviewed?
- Has the system been tested against reconstruction-style attacks?
- Does the model retain excessive memorisation from sensitive datasets?
This is where structured AI security assessments become useful. QualySec’s three-layer testing approach combines automated discovery, AI-assisted analysis, and manual validation to identify weaknesses across deployed AI systems. Automated checks surface known exposure patterns quickly, while human-led review focuses on chained attack paths and subtle leakage conditions that generic tooling often misses.
Explore how QualySec’s AI security assessments help organisations identify model inversion risk before production systems become an exposure point.
Learn how our team uses automated discovery and manual validation to protect your enterprise models. Get a structured AI Security review with an expert.
Talk to our Cybersecurity Expert to discuss your specific needs and how we can help your business.

Conclusion
For a long time, most security discussions around AI focused on poisoned datasets, hallucinations, or model misuse. Model inversion attacks changed that conversation. The risk is no longer limited to what a model produces. It now includes what the model quietly remembers.
That distinction matters because many organisations still approach AI security like traditional application security. They secure storage layers, restrict database access, harden cloud infrastructure, and then assume the trained model is safe by extension. In practice, the model itself can become the exposure point.
The bigger issue is visibility. Most teams cannot clearly answer basic questions about their deployed models:
- Which systems expose confidence scores?
- Which APIs can be queried without meaningful restrictions?
- Which models were trained on regulated or biometric data?
- Where does memorisation risk become excessive?
Those gaps are exactly what inversion attacks exploit.
Regulators have already started reacting. OWASP formally classifies model inversion as ML03:2023. NIST addresses reconstruction attacks in its AI 100-2 E2025 privacy taxonomy. The European Data Protection Board has raised the possibility that certain trained AI models may themselves qualify as personal data under GDPR. That should get leadership attention.
For security teams, the practical takeaway is fairly direct. AI systems need the same scrutiny organisations already apply to infrastructure, endpoints, and cloud assets. Maybe more in some cases. Once sensitive data is reconstructed from a deployed model, the damage is rarely contained to one environment or one incident cycle. Biometric exposure, medical records, behavioural data, and financial attributes do not reset cleanly after compromise.
The organisations handling this well are no longer treating AI security as a future problem. They are testing models before deployment, restricting unnecessary outputs, monitoring inference behaviour closely, and reviewing AI APIs with the same seriousness applied to public-facing infrastructure.
That shift is already happening. Slowly in some sectors. Faster in others. But it is happening.
Frequently Asked Questions
1. What are the four phases involved in a model inversion attack?
The attack usually begins with reconnaissance of the model’s API and outputs. This is followed by crafting synthetic probe queries, analysing output patterns over hundreds or thousands of requests, and finally reconstructing sensitive features from the training data.
2. How is model inversion different from model extraction?
The two attacks are related, but they go after different things. Model inversion is about the data behind the model. The attacker wants information that appeared in training records, such as medical details, biometric traits, or financial attributes. Model extraction is different. There, the objective is to copy the model itself closely enough to reproduce its behaviour or commercial value.
3. Has a model inversion attack happened in the real world?
Yes. One of the best documented examples appeared in academic research presented at ACM CCS in 2015. Researchers demonstrated that facial images could be reconstructed from a recognition model using confidence outputs returned by the system. A related 2014 study on a warfarin dosing model showed similar techniques exposing patients’ genetic markers.
4. Why do security teams treat these attacks seriously?
Because the exposure happens through normal inference activity. No one needs to break into a database first. That changes how the incident appears from a monitoring standpoint. In biometric systems especially, the consequences are difficult to reverse since faces, fingerprints, and genetic traits cannot simply be rotated the way passwords can.
5. What actually reduces the risk of model inversion?
There is no single fix that solves it entirely. Most organisations combine multiple controls: limiting confidence-score exposure, introducing differential privacy during training, tightening API access policies, monitoring for abnormal query behaviour, and running threat-modelling exercises before deployment. The common thread across current guidance is reducing how much information the model reveals during inference.
6. Which sectors tend to face the highest exposure?
Healthcare usually sits near the top because clinical AI systems are trained on medical records, diagnostic scans, genomic data, and prescription information. Financial platforms are also heavily exposed due to fraud models and behavioural analytics trained on customer transactions. Biometric authentication systems remain another major concern because reconstructed identifiers are effectively permanent once exposed.














































































































































































































































































































































































































































































































































































































0 Comments